



딥러닝 워드투벡 블로그 텍스트 생성 해보기!
2020. 12. 30. 06:23
이번 포스팅에서 원핫인코딩을 이용한 블로그 텍스트 생성과 워드투벡에 대해서 알아보았다. 오늘은 앞에서 다룬 내용을 토대로 워드투벡을 이용한 블로그 텍스트를 생성해보고자 한다. 딥러닝 프레임웍은 케라스를 이용해보았다. 케라스보다는 파이토치를 학습하는 것이 목표이기 때문에, 케라스를 이용한 방법은 가볍게 시도해보고 넘어가기로 하였다.

GPU를 사용하기 위해, 구글 코랩을 사용하고 있다. 구글 코랩에서 GPU를 사용하고 있는지 확인하기 위해서는 런타임 환경을 살펴봐야 한다. 구글 코랩 상단의 [런타임] - [런타임 유형 변경] 을 선택하면 아래와 팝업을 볼 수 있다. 하드웨어 가속기를 GPU로 선택하면, GPU를 이용할 수 있다.

케라스에서 GPU를 사용할 수 있는지 확인해보려고 했는데, 쉽지가 않았다. 그래서 그냥 텐서플로우에서 GPU모듈을 확인해보았다.
!nvidia-smiimport tensorflow as tf
tf.test.is_gpu_available()
다음 필요한 모듈과 데이터를 불러왔다.
import sys
sys.path.append('/content')
import pandas as pd
import pickle
from textprepr import TextPreprocessing
import sqlite3
import numpy as np
from tqdm import tqdm
con = sqlite3.connect("/content/post_data.db")
df = pd.read_sql("SELECT * FROM total_df", con)
다음으로 gensim패키지와 워드투벡으로 임베딩할 수 있는 클래스를 만들었다. 예측 단어는 예측된 벡터에서 가장 가까운 단어를 추출하는 것으로 만들었다. 하지만, 이렇게 하니 생각보다 결과가 잘 나오지는 않았다. 인터넷에 검색해보니 학습대상을 원-핫 인코딩으로 구분된 단어를 이용해서 하는 케이스를 봤는데, 해당 케이스가 결과가 더 잘 나오지 않을까 싶다.
import gensim
class MyWord2Vec:
"""
토큰화된 텍스트를 워드투벡으로 임베딩해서 반환
"""
def __init__(self, file="/content/ko_new.bin"):
self.model = gensim.models.Word2Vec.load(file)
def to_w2v(self, pos):
"""
pos:단어,, 워드투벡으로 임베딩
"""
try:
pos_vec = self.model.wv.get_vector(pos)
except:
pos_vec = np.zeros(200, )
return pos_vec
def get_predict_words(self, predict):
return self.model.wv.most_similar(positive=predict, topn=1)[0][0]w2v = MyWord2Vec()
다음으로 문장을 워드투벡으로 변경하는 함수를 만들었다.
x_len = 20
vec_size = 200
def make_df_vec(content_pos, x_len=x_len):
"""
여러 단어를 워드투벡으로 변경하기
"""
data = list()
for i in range(len(content_pos) - x_len):
data.append(content_pos[i:i+x_len])
tot_list = list()
for d in data:
temp_list = np.array([w2v.to_w2v(pos) for pos in d])
tot_list.append(temp_list)
np_data = np.array(tot_list)
return np_data
텍스트를 전처리하고, 토큰 단위로 분류하였다.
tp = TextPreprocessing()
tot_list = [tp.tagging(x) for x in df["content"]]
텍스트를 워드투벡 표현으로 바꿔주었다.
np_data = np.empty(shape=(0,20,vec_size))
for x in tqdm(tot_list):
if len(x)>=20:
temp = make_df_vec(x)
np_data=np.vstack((np_data, temp))
else:
pass
문장을 섞어주는 게 좋을 것 같아, shuffle로 섞고 나서 train셋과 test셋으로 분리해보았다.
np.random.shuffle(np_data)
x_train = np_data[:, 0:19, :]
y_train = np_data[:, 19, :]
다음으로 keras를 이용해서 모델을 만들어보았다.
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense, Activation, Bidirectional, BatchNormalization
from keras.callbacks import EarlyStopping
from keras import optimizers
len_pos_dic = 200
# opt = optimizers.Adam(learning_rage=0.02)
model = Sequential()
model.add(Bidirectional(LSTM(200, activation="relu"), input_shape=(x_len-1, len_pos_dic)))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(300, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(300, activation='relu'))
model.add(Dense(len_pos_dic, activation='relu'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=["mae"])
model.summary()
적은 학습으로도 결과를 잘 내보고자, learning rate를 임의로 변경되도록 설정해보았다. learnging schedule은 많이 쓰는 방법은 아니고, 필자가 임의로 만들어보았다.
from keras.callbacks import LearningRateScheduler
learning_schedule=LearningRateScheduler(lambda epoch: 0.004 * (0.5**int((epoch+5)/5)))
callbacks = [EarlyStopping(patience=3, monitor='loss')]
history=model.fit(x_train, y_train, batch_size=300, epochs=100, callbacks=callbacks)
loss를 history에 값으로 저장하고 그래프르 그려보았다.
import matplotlib.pyplot as plt
history_dict = history.history
loss=history_dict["loss"]
epochs=range(1,len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Traing loss')
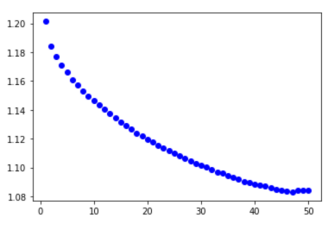
아래와 같이 최종 loss값을 추력해보았다. 값은 1.0841249의 값이나왔다.
loss[-1]
마지막으로 값을 예측하고 얼마나 맞출 수 있는지 출력해보았다.
# 예측
pos_tag_list = tp.tagging(df["content"][0])
pred = make_df_vec(pos_tag_list)
x_pred = pred[:,0:19,:]
y_pred = pred[:, 19, :]
predict = model.predict(x_pred[0].reshape(1, x_len-1, len_pos_dic))
is_right = 0
tot = 0
for i in range(0, x_pred.shape[0]):
for word_vec in x_pred[i]:
word=w2v.get_predict_words([word_vec])
print(word, end=",")
predict=model.predict(x_pred[i].reshape(1,x_len-1,len_pos_dic))
pre_pos=w2v.get_predict_words(predict)
real_word = w2v.get_predict_words([y_pred[i]])
print("|predict={} | real={}".format(pre_pos, real_word))
tot +=1
if pre_pos==real_word:
is_right+=1
if i==50:
print("전체 갯수:{}, 최종 맞춘 갯수: {}".format(tot, is_right))
break

51개를 테스트 해 본 결과 13개를 맞추었다. 앞에 원핫-인코딩보다는 낫지만, 만족스러운 결과라고 하기는 어렵다. 하지만, 학습을 목적으로 하기 때문에 빠르게 pytorch를 이용한 방법으로 넘어가기로 하였다.
| 파이토치 torchvision 이미지 딥러닝 모델 알아보기 (0) | 2021.02.17 |
|---|---|
| 파이토치, 워드투벡 텍스트 딥러닝 해보기 (0) | 2021.01.06 |
| 워드투벡 단어 추가 및 학습시키는 방법은?! (1) | 2020.12.24 |
| 워드투벡 의미와 한글에 적용하는 방법은?! (0) | 2020.12.23 |
| 딥러닝 용어(2/2) - 손실함수, 배치크기, 에포크, 학습률 (1) | 2020.12.20 |