



워드투벡 의미와 한글에 적용하는 방법은?!
2020. 12. 23. 06:23
텍스트 관련 딥러닝을 다루면서, 워드투벡은 꼭 한 번 집고 넘어가는 중요한 부분이다. 원드투벡은 워드 임베딩의 한 방법이다. 원핫 인코딩은 단어를 0과 1로 표현하지만, 워드투벡에서는 일정한 길이의 벡터로 표시된다.
이 벡터를 구하기 위해서는 인공신경망을 이용한다. 워드투벡은 특정 단어는 문장의 앞뒤에 나온 다른 단어들로 설명할 수 있다는 개념이다. 그래서 앞뒤 주변 단어들을 입력으로 넣고, 가운데에 있는 단어를 출력으로 놓는다. 은닉층을 1개로 놓고 학습을 시킨 후, 이 은닉충과 가중치를 선택하여 워드투벡을 만들게 된다. 워드투벡에 대한 자세한 설명은 아래 링크에 잘 되어 있으니, 참고하기 바란다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
워드투벡은 직접 만들 수도 있지만, 이미 만들어진 모델에 추가로 필요한 데이터만 학습하여 사용할 수도 있다. 직접 만든다고 하면, 아래와 같이 gensim패키지를 이용하여 만들어 볼 수 있다. gensim은 토픽 모델링, 문서 인덱싱, 유사성 검색 등을 위한 자연어 처리 패키지이다. 워드투벡 이외에도 다른 기능들이 많지만, 한국어에서는 사용하기 조금 어렵다.
from gensim.models import Word2Vec
model = Word2Vec(sentences=tokenized_data, size=100, window=5, min_count=5, workers=4, sg=0)
model.wv.vectors.shape
tokenized_data는 앞에서 다룬 형태소별로 분리한 데이터이다. 위의 결과 2391 x 100 사이즈의 벡터가 만들어졌다.
여기서는 직접 만들기보다는 이미 만들어진 '워드투벡'에 추가로 학습하여 사용하고자 한다. 미리 학습된 한국어 워드투벡 모델은 박규병님의 깃허브에 공개되어 있다.
Kyubyong/wordvectors
Pre-trained word vectors of 30+ languages. Contribute to Kyubyong/wordvectors development by creating an account on GitHub.
github.com
공개한 다운로드 경로는 아래와 같다.
- 워드투벡 모델 다운로드 경로: https://drive.google.com/file/d/0B0ZXk88koS2KbDhXdWg1Q2RydlU/view
데이터를 불러온 후에 NULL값이 있는지 확인해본다. values는 데이터프레임을 numpy로 바꿔준다. 이후에 any()함수를 사용해서 True값이 하나라도 있는지 확인한다.
df_content.isnull().values.any()
다음 블로그 데이터를 토큰화한다.
textpr = tp.TextPreprocessing()
tokenized_data = [textpr.tagging(x) for x in df_content]
토큰화된 데이터를 일부 살펴보았다. 먼저 가장 많은 토큰을 가진 포스팅은 몇 개나 가지고 있는지 알아보았다.
print("최대길이 :", max(len(l) for l in tokenized_data))
print("평균길이 :", sum(map(len, tokenized_data)) / len(tokenized_data))
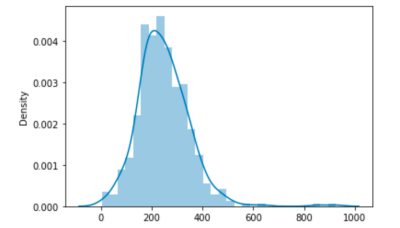
실행해 본 결과 최대길이 926, 평균길이 247.7이 나왔다.
import seaborn as sns
sns.distplot([len(s) for s in tokenized_data ])
사전에 학습된 모델을 불러온다.
import gensim
model = gensim.models.Word2Vec.load("ko.bin")
벡터 크기와 단어 갯수를 출력해보았다.
model.wv.vector_size
len(model.wv.vocab)
벡터 크기는 200이고, 단어의 갯수는 30,185개이다.
코퍼스의 크기는 아래와 같이 확인할 수 있다. 총 2,203,153개의 코퍼스가 있다.
model.corpus_count
아래와 같이 단어에 빅데이터가 있는지 확인해 보았지만, 없었다.
word="빅데이터"
try:
model.wv.most_similar(word)
except:
print("{}: 없음".format(word))

포스팅을 차례로 작성하다보니 생각보다 내용이 길어졌다. 사전에 학습된 워드투벡에 추가로 학습시키는 내용에 대해서 다음 포스팅에서 다뤄보도록 하겠다.
| 딥러닝 워드투벡 블로그 텍스트 생성 해보기! (0) | 2020.12.30 |
|---|---|
| 워드투벡 단어 추가 및 학습시키는 방법은?! (1) | 2020.12.24 |
| 딥러닝 용어(2/2) - 손실함수, 배치크기, 에포크, 학습률 (1) | 2020.12.20 |
| 딥러닝 관련 용어(1/2) - 활성화 함수, 옵티마이저 (0) | 2020.12.18 |
| 원핫인코딩 텍스트 생성 딥러닝 학습하기 (1) | 2020.12.16 |